
Význam a potřeba zavádění dohledových a monitorovacích systémů v současném světě IT neustále stoupá se stále rostoucí složitostí provozovaných aplikací, technologií, informačních systémů, ale i komplexních služeb ICT nebo celých business procesů. Obchodní aktivity společností jsou stále více závislé na informatice a prostředcích IT, a proto mají případné výpadky či defekty infrastruktury IS/ICT klíčové dopady na jejich business.
Proč monitorovat ICT?
Informace v ucelené podobě získané z monitoringu vytvářejí nástroj podporující rozhodování o klíčových otázkách na všech úrovních řízení ICT. Z hlediska operativního řízení pomáhají identifikovat a řešit aktuální problémy v dostupnosti a výkonnosti služeb a aplikací ICT na základě okamžitých informací. Na druhé straně statistické informace jako výstup monitorování charakterizují chování koncových uživatelů (např. v jakou dobu je služba nejvíce, popř. nejméně využívána), a tím pomáhají např. s plánováním odstávek technologií. Obdobně informace o využívání služeb koncovými zákazníky používá marketingové oddělení při plánování marketingových kampaní. Z hlediska taktického a strategického řízení pak slouží v delším časovém horizontu jako nástroj podpory rozhodování o změnách, rozvoji a plánování kapacit ICT.
Fault management
V dnešním podnikovém prostředí stále více rezonuje potřeba řešení výpadků počítačových a telekomunikačních sítí a elementů rozsáhlých infrastruktur ICT. V dnešních komplexních sítích, systémech, aplikacích a celých službách vzniká velké množství událostí, a proto se jejich správa a provoz stává náročnějším úkolem, který je bezpochyby potřeba automatizovat. Postupně se tedy odstupuje od manuálního řešení vzniklých problémů, a tak se stává automatizace procesu řízení a správy informačních technologií nezbytnou. Fault management je jednou z disciplín v rámci řízení ICT představující rozsáhlou skupinu automatizovaných funkcí, které mají za úkol odhalit, izolovat a opravit výpadky či defekty v sítích a všech ostatních prvcích, jakými jsou routery, servery, systémy, aplikace apod. Jedním z nástrojů fault managementu je stavový monitoring.
Performance management
Performance management představuje soustavu nástrojů a procesů monitorující výkonnost sítě a jejích prvků, aplikací, systémů, serverů a následně i služeb ICT na nich provozovaných. Hlavními nástroji podporujícími řízení výkonnosti jsou monitorování výkonnosti, E2E (End To End) monitorování a transakční monitorování. Hlavním rozdílem mezi monitorováním výkonnosti a stavovým monitorováním lze nalézt primárně ve způsobu získávání monitorovacích dat a následně i v jejich prezentaci. Zatímco v případě stavového monitorování jsou generovány a následně zpracovány události, které představují výpadky jednotlivých částí infrastruktury ICT, které jsou následně prezentovány ve formě alarmů v rámci dohledového systému, při monitorování výkonnosti jsou monitorovací data sbírána v pravidelných intervalech, ukládána do performance management databáze a následně vyhodnocována. Nástroje performance management tak poskytují svým uživatelům spojitý pohled na získaná data, a tedy i spojitý pohled na výkonnost technologií, aplikací, služeb ICT nebo business procesů. Díky těmto datům jsou podniky schopné určit výkonnost v rámci dlouhých časových intervalů např. za období jednoho čtvrtletí, pololetí či roku.
Procesy
Každé nasazení dohledového systému vyžaduje definici procesů spojených s jeho provozem a vyhodnocováním získaných informací. Tyto procesy je nezbytné implementovat v souladu s použitým metodickým rámcem pro řízení ICT (ITIL, COBIT apod.). Ze zkušeností společnosti RYANT je implementaci monitoringu vhodné provést podle předem stanovených standardizovaných postupů a procesů, které vedou k časově a nákladově efektivním nasazením.
Nástroje
- IMB/Tivoli Netcool - balík produktů původně od společnosti Micromuse, která byla v roce 2006 koupena společností IBM. Platforma je vhodná pro implementaci stavového monitorování, service managementu a vyhodnocení parametrů SLA. Hlavní výhody platformy jsou: značné možnosti integrace s dohledovými systémy třetích stran a vysoká výkonnost a škálovatelnost.
- InfoVista - balík produktů pro podporu performance managementu od stejnojmenného dodavatele. Platforma je vhodná pro zabezpečení monitoringu výkonnosti sítě, aplikací a reportování úrovně kvality služeb.
- Nagios - oblíbené open-source řešení pro monitoring stavu počítačové sítě a dalších prvků infrastruktury. Výhodou je již velké množství hotových doplňků pro monitoring mnoha metrik.
Reference
Společnost RYANT se podílela ve spolupráci s NextiraOne Czech (dnes Dimension Data) na následujících projektech:
- T-Mobile Czech Republic, a.s. - nasazení fault management nástrojů na platformě Netcool a s ním spojené konzultace, analýzy a implementace dohledů jednotlivých služeb ICT a dále nasazení a provoz E2E a transakčního monitorování vybraných 45 služeb ICT (včetně Genesys - platformy pro podporu řízení call centra).
- ČSOB, a.s. - nasazení a provoz centrálního dohledového systému na platformě Netcool, integrace dílčích technologií do centrálního management systému, implementace a provoz bezpečnostního monitoringu na platformě NfSM (Netcool for Security Management) a E2E monitoringu s nástroji InfoVista a NewTest.
- Ministerstvo vnitra České republiky - implementace a provoz dohledu na platformě Netcool, integrace s helpdesk nástrojem Omnitracker.
Společnost RYANT aplikuje monitoring své vlastní infrastruktury včetně bezmála dvou set zákaznických serverů na platformě Nagios. Tímto systémem je nepřetržitě sledováno několik tisíc dílčích aplikací a služeb.
Základní služba
Základní služba je určena pro menší a střední firmy (s maximálně pěti servery). Po zpřístupnění serveru (např. pro Windows Server po nainstalování NSClient++ začne poskytovatel monitorovat jak hardware (standardně zejména využití disků, procesorů a paměti), tak služby nad tímto hardware běžící. Pro monitoring je použit systém Nagios.
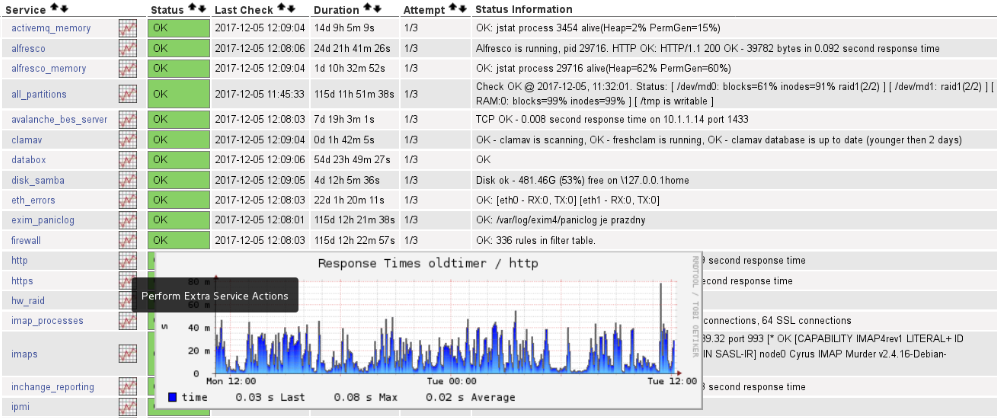 Ukázka webového rozhraní systému Nagios
Ukázka webového rozhraní systému Nagios
Zákazníci mají možnost přistupovat na stavové reporty svých serverů prostřednictvím webového rozhraní Nagiosu. Součástí služby je samozřejmě podání stavové informace i informace o (potenciálních) problémech s hardware či službami. Tyto informace jsou poskytovány dle přání zákazníka:
- přes webové rozhraní;
- prostřednictvím e-mailu zaslaného na adresy určené zákazníkem;
- prostřednictvím SMS zaslané na čísla určená zákazníkem;
- prozváněním telefonních čísel určených zákazníkem ve stanoveném pořadí (vhodné zejména pro kritické závady, jež se vyskytnou v noci).
Na základě dohody lze doobjednat další služby, např.:
- provedení aktualizace operačního systému či nad ním nainstalovaného software;
- kontrolu logů;
- kontrolu kvality použitých hesel;
- detekci nepoužívaných účtů;
- penetrační testy;
- jakékoli analytické činnosti nad daným serverem.